
1. Das Datendilemma in der generativen KI
Generative KI bezeichnet einen Teilbereich der künstlichen Intelligenz, der neue Inhalte – Bilder, Texte, Audio, Videos und mehr – basierend auf Mustern erstellt, die er aus vorhandenen Daten lernt. Dies wirft die Frage auf, welche Herausforderungen er im Umgang mit Daten bewältigen muss. Tools wie ChatGPT, DALL·E und Stable Diffusion sind beliebte Beispiele, die das branchenübergreifende Potenzial generativer KI veranschaulichen. Diese beeindruckende Technologie bringt jedoch eine entscheidende Abhängigkeit mit sich: hochwertige, groß angelegte Datensätze.
Um gute Ergebnisse zu erzielen, müssen generative KI-Modelle mit riesigen Datenmengen trainiert werden, die nicht nur sauber und vielfältig, sondern auch ethisch einwandfrei sind. Dies führt zu einem erheblichen Spannungsfeld zwischen Innovation und Verantwortung. Schlechte Datenqualität kann zu irreführenden Ergebnissen führen; verzerrte Datensätze können schädliche Stereotypen verstärken; und die unregulierte Nutzung personenbezogener Daten kann Datenschutzbedenken auslösen.
Kurz gesagt: Der Treibstoff, der die generative KI antreibt, birgt auch ihre größten Schwachstellen.
Verständnis Welche Herausforderungen bestehen für generative KI im Hinblick auf Daten? ist für den Aufbau vertrauenswürdiger KI-Systeme unerlässlich. Dieser Blog untersucht diese Herausforderungen eingehend – von Datenverzerrung und Datenschutz bis hin zur Datenherkunft – und präsentiert eine zukunftsweisende Lösung: Person generieren von PiktID. Dieses Tool hilft Benutzern, Identitäten in Datensätzen zu schützen, indem es Personen in Bildern ersetzt oder anonymisiert, ohne den Realismus zu beeinträchtigen.
2. Vor welcher Herausforderung steht die generative KI im Hinblick auf Daten?

Welche Herausforderungen ergeben sich für die generative KI im Hinblick auf Daten?
Generative KI steht vor großen datenbezogenen Herausforderungen wie schlechter Datenqualität, inhärenten Verzerrungen, mangelndem Datenschutz und unklarer Datenherkunft. Diese Probleme können zu fehlerhaften Inhalten, ethischen Risiken und einem verringerten öffentlichen Vertrauen in KI-Systeme führen.
Eine der größten Herausforderungen der generativen KI ist Sicherstellung der DatenqualitätWenn ein Modell mit verrauschten, falsch beschrifteten oder unvollständigen Datensätzen trainiert wird, sind die Ergebnisse ungenau oder unsinnig. Beispielsweise kann eine KI, die mit schlecht beschrifteten Gesichtsbildern trainiert wurde, bei der Erstellung neuer Gesichter verzerrte Ergebnisse liefern.
Dann kommt Voreingenommenheit– ein weit verbreitetes Problem, das entsteht, wenn Trainingsdaten bestimmte Gruppen über- oder unterrepräsentieren. Ein klassischer Fall ist eine KI zur Lebenslauffilterung, die hauptsächlich auf männliche Bewerber trainiert wurde, was zu diskriminierenden Einstellungsvorschlägen führte. Ähnlich verhält es sich mit Bildgenerierungsmodellen, die dazu neigen, bestimmte ethnische oder geschlechtliche Erscheinungen zu bevorzugen und so Stereotype zu verstärken, anstatt sie zu hinterfragen.
Datenschutz Ein weiteres zentrales Problem ist die Gefahr. Generative Modelle können sich manchmal Teile ihrer Trainingsdaten merken und unbeabsichtigt persönliche Informationen wie Gesichter oder Namen reproduzieren. Dies wirft ernsthafte ethische Fragen darüber auf, ob menschliche Daten – insbesondere von öffentlich zugänglichen Websites – jemals für das KI-Training verwendet werden sollten.
Schließlich, DatenherkunftDie Rückverfolgbarkeit der Datenherkunft ist oft unklar. KI-Entwickler wissen nicht immer, ob die von ihnen verwendeten Daten aus ethischen Quellen stammen, ordnungsgemäß lizenziert sind oder überhaupt legal genutzt werden können. Dies birgt rechtliche Risiken und Reputationsrisiken, insbesondere bei kommerziellen Anwendungen.
Bei der Bewertung Welche Herausforderungen bestehen für generative KI im Hinblick auf Daten?ist klar, dass es sich hierbei nicht nur um technische Hürden handelt, sondern um grundlegende Fragen zu Ethik, Eigentum und Verantwortlichkeit bei der Entwicklung künstlicher Intelligenz.
3. Datenqualität: Garbage In, Garbage Out

Wenn Sie fragen Welche Herausforderungen bestehen für generative KI im Hinblick auf Daten?ist eines der dringendsten Probleme DatenqualitätGenerative KI-Systeme, egal ob sie Bilder, Texte oder Audiodateien produzieren, sind nur so gut wie die Daten, mit denen sie trainiert werden. Sind diese Daten falsch gekennzeichnet, verzerrt, unvollständig oder von schlechter Qualität, spiegeln sich diese Mängel in der Ausgabe wider – oft auf eine Weise, die erst zu spät erkannt wird.
Stellen Sie sich ein Textgenerierungsmodell vor, das mit veralteten oder ungenauen medizinischen Daten trainiert wurde. Die KI könnte zwar Gesundheitsratschläge erstellen, die zwar plausibel klingen, aber medizinisch falsch sind. Bei der Bildgenerierung können minderwertige oder schlecht kommentierte Bilder zu verzerrten Gesichtern, ungenauen Hauttönen oder anstößigen Darstellungen führen – insbesondere in sensiblen Kontexten wie Rasse oder Geschlecht. Beispielsweise könnte eine KI, die mit niedrig aufgelösten Bildern von Prominenten trainiert wurde, bei der Anwendung auf reale Personen Gesichtszüge halluzinieren. Im Audiobereich können minderwertige Trainingsdaten zu einer roboterhaften oder unverständlichen Sprachsynthese führen, der die für Barrierefreiheit oder virtuelle Assistenten erforderliche emotionale Nuance fehlt.
Dies ist besonders schädlich in Bereichen mit hohem Einsatz wie Gesundheitspflege und FinanzenIm Gesundheitswesen könnte ein KI-gestütztes Diagnosetool, das auf fehlerhaften Daten trainiert wurde, Tumore falsch identifizieren und so zu einer falschen Behandlung führen. Im Finanzwesen könnte ein generatives Modell, das auf verzerrten Wirtschaftsindikatoren trainiert wurde, unrealistische Prognosen liefern und so Investitionsentscheidungen oder Kundenportfolios schädigen.
Kurz gesagt: Das Prinzip „Garbage in, Garbage out“ ist eine direkte Antwort auf die Herausforderung, vor der generative KI in Bezug auf Daten steht: Wenn die Eingabedaten beschädigt sind, leidet die gesamte KI-Pipeline.
Lesen Sie unseren ausführlichen Leitfaden über KI-Modemodell-Generator für globale Kampagnen
4. Datenschutzbedenken: Ist Ihr Gesicht in einem Datensatz?

Ein weiterer wichtiger Bestandteil bei der Beantwortung Welche Herausforderungen bestehen für generative KI im Hinblick auf Daten? Ist Datenschutz– insbesondere, wie leicht KI-Systeme missbraucht werden oder Informationen preisgeben können persönlich identifizierbare Informationen (PII)Generative Modelle, insbesondere solche zur Gesichtserkennung, Stimmklonierung und personalisierten Inhaltserstellung, nutzen oft riesige Mengen öffentlich verfügbarer Daten. Das Problem? Viele dieser Daten enthalten Bilder und persönliche Daten, die nie für Schulungszwecke gedacht waren.
Beispielsweise könnte jemand feststellen, dass sein Foto – ursprünglich in sozialen Medien oder einem Blog geteilt – von einer KI zweckentfremdet wird, um ohne seine Zustimmung synthetische Gesichter, Deepfakes oder Avatare zu generieren. Selbst wenn die Daten technisch gesehen „öffentlich“ waren, stammten sie weder aus ethischen Quellen noch waren sie für die Wiederverwendung freigegeben. Diese Grauzone hat öffentliche Reaktionen und rechtliche Fragen ausgelöst. Im Jahr 2020 wurde Clearview AI verklagt, weil das Unternehmen ohne Zustimmung Milliarden von Gesichtsbildern aus dem Internet gesammelt hatte, was Bedenken hinsichtlich Überwachung und Datenmissbrauch aufkommen ließ.
Darüber hinaus können generative KI-Modelle sensible Daten speichern und unbeabsichtigt reproduzieren, wie Namen, Adressen und sogar biometrische Merkmale, sofern diese Daten während des Trainings vorhanden waren. Dies setzt Benutzer Identitätsdiebstahl, Rufschädigung oder unbefugter Profilerstellung aus.
Bei der Bewertung Welche Herausforderungen bestehen für generative KI im Hinblick auf Daten?wird deutlich, dass Datenschutz ist mehr als eine rechtliche Formalität – es ist eine grundlegende Vertrauensfrage. Tools wie Person generieren von PiktID Helfen Sie mit, dieses Problem zu lösen, indem Sie Benutzern die Möglichkeit geben, ihre Bilder zu anonymisieren, bevor sie Teil eines Datensatzes werden. So verringern Sie das Risiko und bewahren gleichzeitig die kreative Freiheit.
Zusätzliche Ressource : Marketing-Tool-Gesichtsgenerator
5. Datenverzerrung: Warum Fairness wichtig ist

Wenn Sie fragen Welche Herausforderungen bestehen für generative KI im Hinblick auf Daten?, eines der kritischsten Probleme ist Verzerrung in DatensätzenGenerative KI lernt, indem sie Muster in großen Datenmengen erkennt. Sind diese Daten jedoch verzerrt – sie bevorzugen bestimmte demografische Merkmale, Tonalitäten, Sprachen oder visuelle Merkmale –, führt dies zu verzerrten Ergebnissen, die schädliche Stereotypen verstärken und zu unfairen Entscheidungen führen.
Beispielsweise werden generative Modelle verwendet in KI-Tools zur Einstellung Geschlechts- und rassistische Vorurteile weisen auf, sodass männliche Kandidaten für Führungspositionen oft höher eingestuft werden als weibliche. Ebenso wurde festgestellt, dass Gesichtserkennungssysteme, die mit unausgewogenen Datensätzen trainiert wurden, Personen aus Minderheitengruppen deutlich häufiger falsch identifizieren als weiße Personen. Diese Diskrepanzen sind nicht nur technische Mängel – sie wirken sich direkt auf die Menschen aus, indem sie den Zugang zu Arbeitsplätzen einschränken, das Überwachungsrisiko erhöhen und Ungleichheit verfestigen.
Die zentrale Herausforderung besteht darin, Ausgleich von Inklusivität mit repräsentativen DatenEinerseits müssen KI-Entwickler sicherstellen, dass alle Gemeinschaften fair repräsentiert sind. Andererseits müssen sie den Datenschutz respektieren und eine Überbefragung sensibler Bevölkerungsgruppen vermeiden. Wenn wir uns fragen, vor welchen Herausforderungen generative KI im Hinblick auf Daten steht, steht die Auseinandersetzung mit eingebetteten gesellschaftlichen Vorurteilen ganz oben auf der Liste – denn verzerrte Daten führen zu voreingenommenen Maschinen.
6. Datenherkunft: Woher stammen die Daten?

Ein weiteres wichtiges Anliegen bei der Beantwortung Welche Herausforderungen bestehen für generative KI im Hinblick auf Daten? ist das Problem von Datenherkunft– die Möglichkeit, Herkunft, Lizenzierung und Weg von Trainingsdatensätzen nachzuverfolgen. Vereinfacht ausgedrückt ist die Provenienz die „Dokumentenspur“ darüber, woher die Daten stammen, wie sie erhoben wurden und ob sie ethisch einwandfrei beschafft wurden.
Dies wird besonders kritisch, wenn generative KI trainiert wird auf Scraped-Daten von Websites, sozialen Plattformen oder akademischen Repositorien, oft ohne das Wissen oder die Zustimmung der Personen, deren Daten verwendet werden. Dies stellt nicht nur ethische Herausforderungen dar, sondern kann auch rechtliche Konsequenzen nach sich ziehen – insbesondere, wenn es sich um urheberrechtlich geschützte oder persönlich identifizierbare Inhalte handelt.
Eines der Kernthemen ist die mangelnde Transparenz in vielen Trainingsdatensätzen. Entwickler nutzen möglicherweise Quellen von Drittanbietern, die selbst nicht ordnungsgemäß dokumentiert sind. Dadurch lässt sich nicht überprüfen, ob die Daten legal oder ethisch vertretbar beschafft wurden. Dies untergräbt das Vertrauen in generative KI-Systeme und setzt Unternehmen der regulatorischen Kontrolle aus.
Wenn man bedenkt Welche Herausforderung bringt generative KI-Gesichtsverbesserung in Bezug auf DatenDie Datenherkunft ist ein grundlegendes Anliegen. Ohne klare Herkunft und Zustimmung ist die Integrität des gesamten KI-Modells gefährdet. Aus ethischen, rechtlichen und leistungsbezogenen Gründen müssen alle zum KI-Training verwendeten Daten nachvollziehbar, dokumentiert und mit den Benutzerrechten in Einklang gebracht werden.
7. Kann generative KI ohne große Datensätze funktionieren?

Eine der dringendsten Fragen in der Welt des maschinellen Lernens lautet: Kann generative KI wirklich ohne riesige Datenmengen funktionieren? Die kurze Antwort lautet: Ja, aber nicht ohne Kompromisse.
Techniken wie Lernen mit wenigen Versuchen und Zero-Shot-Lernen haben sich als Alternative zu traditionellen datenintensiven Ansätzen herauskristallisiert. Diese Methoden ermöglichen es Modellen, Aufgaben mit begrenzten oder sogar gar keinen direkten Beispielen auszuführen, indem sie vorab trainiertes Wissen nutzen und sich schnell an neue Szenarien anpassen. Obwohl sie vielversprechend sind, basieren sie immer noch auf umfangreichen vortrainierte Modelle die zunächst anhand riesiger Datensätze trainiert wurden. Die Herausforderung wird also nicht vollständig vermieden, sondern nur nach oben verlagert.
Dies bringt uns zurück zu einem zentralen Thema: Welche Herausforderungen ergeben sich für die generative KI im Hinblick auf Daten? Die Antwort liegt in der Balance zwischen Innovation und Verantwortung. Selbst fortschrittliche Techniken können die Notwendigkeit von vielfältige, ethisch einwandfreie und qualitativ hochwertige DatensätzeOhne sie besteht die Gefahr, dass die Ergebnisse ungenau, verzerrt oder sogar schädlich sind.
Kleinere Datensätze, insbesondere wenn sie verzerrt oder schlecht beschriftet sind, können die Generalisierbarkeit des Modells einschränken und versteckte Verzerrungen einführen. Darüber hinaus ist die Abhängigkeit von öffentlich gescrapede oder nicht verifizierte Daten kann zu Datenschutzverletzungen und rechtlichen Problemen führen. Daher sind eine verantwortungsvolle Datenbeschaffung und Anonymisierungstools unerlässlich.
8. Lösung im Fokus: Fotos anonymisieren mit Generate Person von PiktID

Um den Datenschutzrisiken im Zusammenhang mit Trainingsdaten zu begegnen, können Tools wie Person generieren von PiktID bieten eine nahtlose Möglichkeit, visuelle Daten zu anonymisieren, ohne den Realismus zu beeinträchtigen.
Egal, ob Sie Datensätze für Forschung, Marketing, Benutzertests oder KI-Training erstellen, Anonymisierung personenbezogener Daten ist nicht mehr optional – es ist unerlässlich. Eine der wichtigsten Antworten auf Welche Herausforderungen bestehen für generative KI im Hinblick auf Daten? liegt in Tools, die die Privatsphäre der Benutzer respektieren und gleichzeitig Innovationen ermöglichen.
Lesen Sie mehr über EraseID-Tutorial die Schritte zur Manipulation von Identität und Gesichtsausdruck zu erlernen und zu verstehen.
So verwenden Sie Generate Person von PiktID:
Schritt 1: Besuchen Sie das Tool
Springe direkt zu: https://studio.piktid.com/generate-person
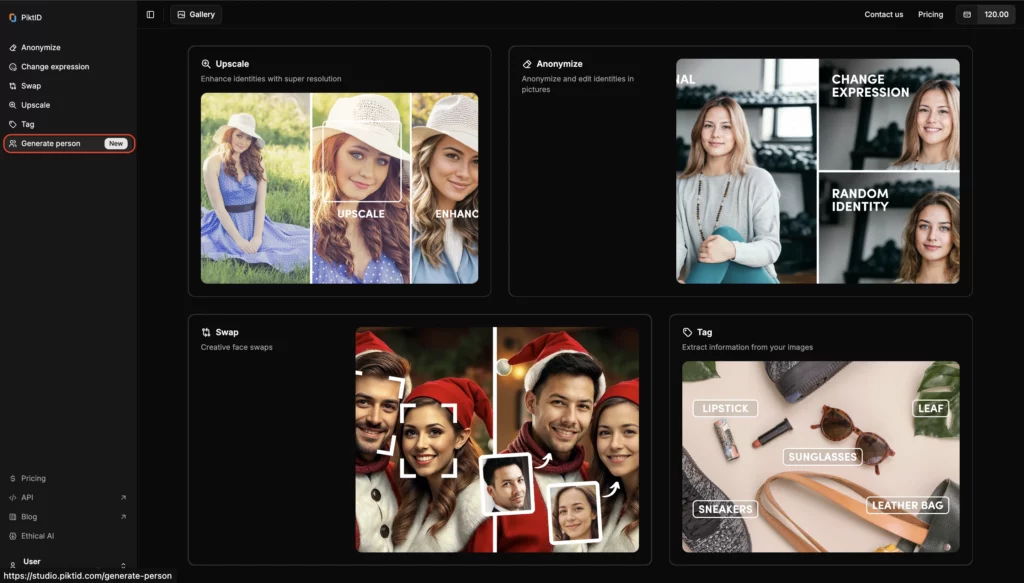
Schritt 2: Ein Bild hochladen
Ziehen Sie ein Bild per Drag & Drop oder wählen Sie es direkt von Ihrem Gerät aus. Dies kann ein persönliches Foto oder ein beliebiges Bild sein, das Sie anonymisieren möchten.
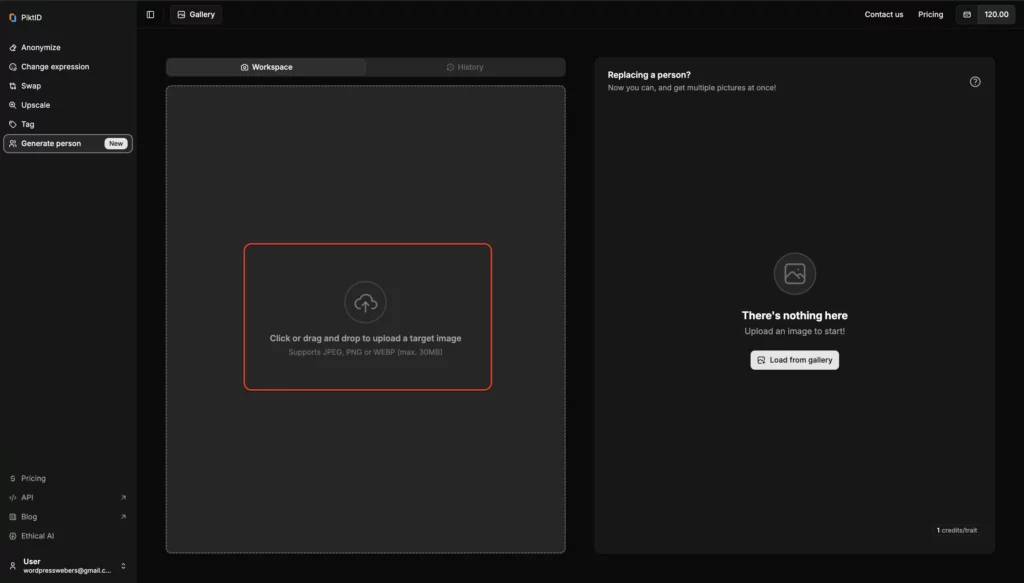
Schritt 3: Wählen Sie eine Person aus, die ersetzt oder geklont werden soll
Wählen Sie in der rechten Benutzeroberfläche die Person auf dem Foto aus, die Sie anonymisieren möchten. Sie können auch einzelne Personen klonen oder ändern.
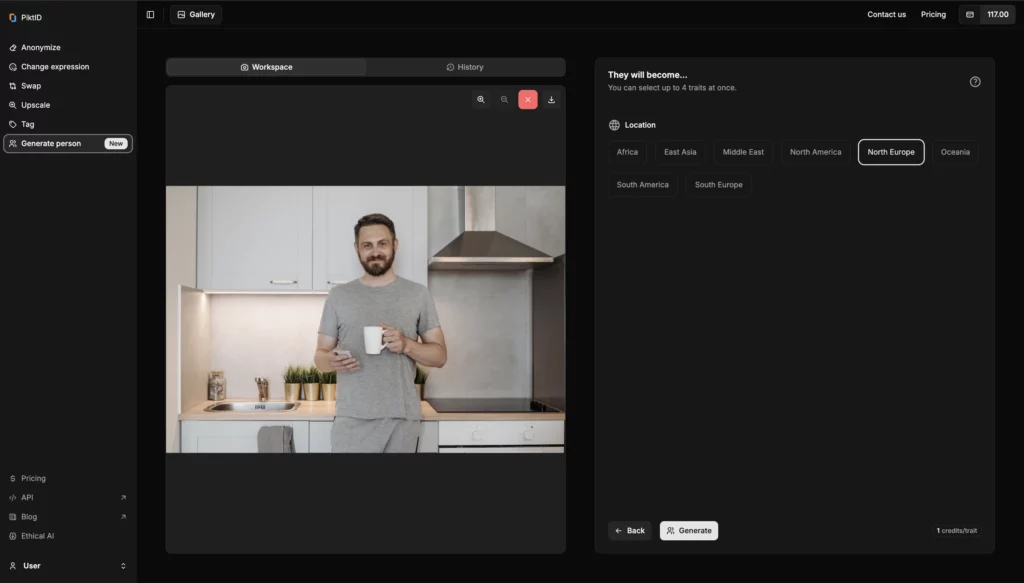
Schritt 4: Klicken Sie auf „Generieren“
Klicken Sie nach der Auswahl auf die Schaltfläche „Generieren“. Die KI verarbeitet das Bild und erstellt eine anonymisierte Version, die Sie im Reiter „Verlauf“ einsehen können.
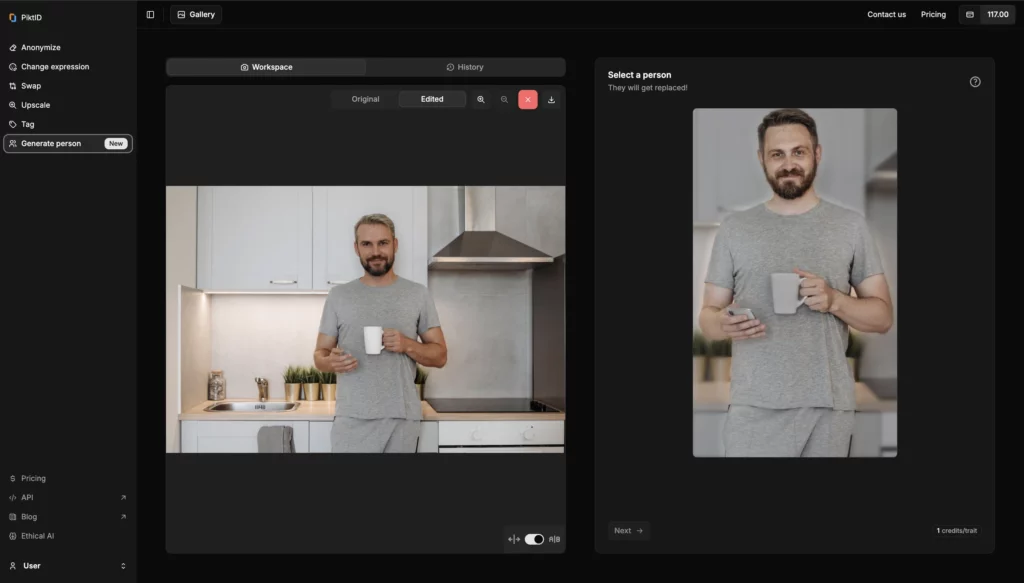
Vorteile von Generate Person:
- Schützt die Privatsphäre: Ersetzt oder ändert automatisch erkennbare Gesichter und verringert so das Risiko eines Missbrauchs.
- Ideal für die Datensatzerstellung: Erstellen Sie KI-Trainingsdatensätze, ohne echte Personen preiszugeben.
- Perfekt für Marketing und UX-Tests: Bewahren Sie den menschlichen Realismus, ohne gegen Datenschutzgesetze zu verstoßen.
- Kein Photoshop erforderlich: Die KI übernimmt alle Bearbeitungen – keine Designkenntnisse erforderlich.
Da Datenschutzbestimmungen wie die DSGVO und der CCPA weltweit verschärft werden, Person generieren ein Kernproblem lösen in Welche Herausforderungen bestehen für generative KI im Hinblick auf Daten?-nämlich, Datenethik, Zustimmung und Sicherheit. Indem Sie Gesichtsdaten im großen Maßstab anonymisieren, unternehmen Sie einen proaktiven Schritt in Richtung einer verantwortungsvollen KI-Entwicklung.
9. Abschließende Gedanken: Auf dem Weg zu einer ethischen und verantwortungsvollen KI
Während wir das transformative Potenzial der künstlichen Intelligenz weiter erforschen, steht eine entscheidende Frage weiterhin im Vordergrund: Welche Herausforderungen ergeben sich für die generative KI im Hinblick auf Daten? Die Antwort liegt in einem komplexen Geflecht von Problemen – von Datenschutz und -sicherheit bis hin zu Voreingenommenheit, Qualitätskontrolle und Herkunft. Diese Herausforderungen sind nicht nur technische Hürden, sondern auch ethische Bedenken, die die Vertrauenswürdigkeit und langfristige Lebensfähigkeit von KI-Systemen bestimmen.
Ohne saubere, vielfältige und verantwortungsvoll beschaffte Daten können selbst die fortschrittlichsten generativen KI-Modelle ungenaue, diskriminierende oder invasiv wirkende Ergebnisse liefern. Deshalb müssen Entwickler, Unternehmen und Einzelpersonen gleichermaßen einem ethischen Umgang mit Daten Priorität einräumen.
Hier kommen Tools wie Person generieren von PiktID spielen eine entscheidende Rolle. Das Tool ermöglicht es Nutzern, Gesichter in Bildern zu anonymisieren und gleichzeitig die Bildqualität zu erhalten. Damit bietet es eine praktische Lösung zum Schutz personenbezogener Daten ohne Kompromisse bei der Funktionalität. Es befasst sich direkt mit einem der dringendsten Probleme der generativen KI: der unbefugten Nutzung und Speicherung identifizierbarer Daten.
In einer Welt, in der KI immer visueller und persönlicher wird, müssen auch die Benutzer besser informiert sein. Verständnis vor welcher Herausforderung generative KI im Hinblick auf Daten steht ist der erste Schritt zur Schaffung verantwortungsvoller digitaler Räume. Ob Sie Datensätze erstellen, Bilder teilen oder einfach nur neugierig sind, wie Ihre Daten verwendet werden – proaktiv zu handeln ist entscheidend.
Werfen Sie einen Blick auf unseren Leitfaden über KI-generierte ID von PiktID.
10. Fordern Sie Ihre kostenlosen Credits an

Übernehmen Sie noch heute die Kontrolle über Ihre Privatsphäre mit Person generieren von PiktID– eine sichere, benutzerfreundliche Lösung zur Anonymisierung von Gesichtsdaten in Sekundenschnelle.
Keine Downloads, keine Komplikationen – laden Sie einfach Ihr Foto hoch, wählen Sie das zu ändernde Gesicht aus und klicken Sie auf „Generieren“. Mit nur wenigen Klicks ist Ihr Bild fertig – Ihre Privatsphäre bleibt gewahrt.
Jetzt starten und genießen 10 kostenlose Kredite, mit keine Anmeldekosten erforderlich. Entdecken Sie die Leistungsfähigkeit ethischer KI-Tools, bei denen die Benutzerkontrolle und die Würde der Daten an erster Stelle stehen.
11. FAQs: Häufige Fragen zu generativer KI und Daten
F1: Was ist heute die größte Herausforderung für generative KI?
Die größte Herausforderung besteht darin, Datenqualität, Verzerrung und Datenschutz in Einklang zu bringen. Ohne saubere, vielfältige und ethisch einwandfreie Datenbeschaffung kann generative KI ungenaue oder schädliche Ergebnisse liefern.
F2: Kann ich verhindern, dass meine Daten für das KI-Training verwendet werden?
Ja, mit datenschutzorientierten Tools wie Generate Person von PiktID können Sie Ihre Fotos anonymisieren. Diese Tools stellen sicher, dass Ihre Daten nicht gespeichert, wiederverwendet oder Trainingsdatensätzen hinzugefügt werden.
F3: Warum ist Voreingenommenheit beim KI-Training gefährlich?
Verzerrungen in Trainingsdaten können zu unfairen, diskriminierenden oder ungenauen Ergebnissen führen. Dies ist besonders schädlich in Bereichen wie Gesichtserkennung, Personalbeschaffung, Kreditvergabe und Gesundheitswesen, wo Fairness von entscheidender Bedeutung ist.
F4: Was macht einen Datensatz für generative KI qualitativ hochwertig?
Ein hochwertiger Datensatz ist vielfältig, gut beschriftet, basiert auf ethischen Grundsätzen und ist frei von Störungen oder Duplikaten. Er sollte reale Unterschiede abbilden, ohne Stereotypen zu verstärken oder wichtige Gruppen auszuschließen.
F5: Ist mein Gesicht sicher, wenn ich es in ein KI-Tool hochlade?
Das hängt von der Plattform ab. Tools wie Generate Person von PiktID legen Wert auf Datenschutz – sie speichern, verwenden oder teilen Ihre Fotos nicht. Wählen Sie immer Plattformen mit klaren, transparenten Datenschutzrichtlinien.
F6: Kann generative KI ohne große Datensätze funktionieren?
Nicht effektiv. Obwohl es Few-Shot- und Zero-Shot-Lerntechniken gibt, funktioniert generative KI am besten mit großen, vielfältigen Datensätzen. Diese Modelle benötigen Vielfalt, um präzise und nützliche Inhalte zu generieren.
F7: Wie verwendet generative KI personenbezogene Daten?
Generative KI kann Spuren personenbezogener Daten aus Trainingsdatensätzen enthalten, auch unbeabsichtigt. Werden die Daten nicht anonymisiert oder nicht freigegeben, kann dies zu Datenschutzrisiken und zur unbefugten Replikation personenbezogener Daten führen.
F8: Was ist Datenherkunft und warum ist sie in der KI wichtig?
Datenherkunft bezieht sich auf die Nachverfolgung der Datenherkunft und ihrer Verwendung. Sie ist für eine ethische KI-Entwicklung unerlässlich und trägt dazu bei, Transparenz, Rechtmäßigkeit und Verantwortlichkeit bei der Schulung von Modellen zu gewährleisten.