
1. Il dilemma dei dati nell'intelligenza artificiale generativa
L'IA generativa si riferisce a un sottoinsieme dell'intelligenza artificiale che crea nuovi contenuti – immagini, testo, audio, video e altro – basandosi su modelli che apprende dai dati esistenti, sollevando interrogativi sulle sfide che deve affrontare in relazione ai dati. Strumenti come ChatGPT, DALL·E e Stable Diffusion sono esempi noti che mostrano il potenziale dell'IA generativa in diversi settori. Tuttavia, questa straordinaria tecnologia presenta una dipendenza critica: set di dati di alta qualità e su larga scala.
Per funzionare al meglio, i modelli di intelligenza artificiale generativa devono essere addestrati su enormi quantità di dati, non solo puliti e diversificati, ma anche provenienti da fonti etiche. Questo crea una forte tensione tra innovazione e responsabilità. Una scarsa qualità dei dati può portare a risultati fuorvianti; set di dati distorti possono rafforzare stereotipi dannosi; e l'uso non regolamentato dei dati personali può sollevare preoccupazioni sulla privacy.
In breve, il carburante che alimenta l'intelligenza artificiale generativa presenta anche le sue maggiori vulnerabilità.
Comprensione quale sfida deve affrontare l'intelligenza artificiale generativa rispetto ai dati è essenziale per la creazione di sistemi di intelligenza artificiale affidabili. Questo blog esplora queste sfide in modo approfondito, dalla distorsione dei dati alla privacy, fino alla provenienza dei dati, e presenta anche una soluzione lungimirante: Genera Persona con PiktIDQuesto strumento aiuta gli utenti a proteggere le identità nei set di dati sostituendo o rendendo anonime le persone nelle immagini senza comprometterne il realismo.
2. Quali sfide deve affrontare l'intelligenza artificiale generativa in relazione ai dati?

Quali sfide deve affrontare l'intelligenza artificiale generativa in relazione ai dati?
L'IA generativa si trova ad affrontare importanti sfide legate ai dati, come la scarsa qualità, i bias intrinseci, la mancanza di riservatezza e la provenienza poco chiara dei dati. Questi problemi possono tradursi in contenuti imperfetti, rischi etici e una riduzione della fiducia del pubblico nei sistemi di IA.
Una delle sfide più grandi dell’intelligenza artificiale generativa è garantire la qualità dei datiSe un modello viene addestrato su set di dati rumorosi, etichettati in modo errato o incompleti, i risultati saranno imprecisi o privi di senso. Ad esempio, un'IA addestrata su immagini facciali etichettate in modo errato potrebbe generare output distorti quando le viene chiesto di creare nuovi volti.
Poi arriva pregiudizio—un problema pervasivo che si verifica quando i dati di training sovrarappresentano o sottorappresentano determinati gruppi. Un caso classico riguarda l'intelligenza artificiale per il filtraggio dei curriculum, addestrata principalmente su candidati di sesso maschile, che ha portato a suggerimenti di assunzione discriminatori. Analogamente, i modelli di generazione di immagini hanno mostrato una tendenza a favorire determinati aspetti razziali o di genere, rafforzando gli stereotipi invece di contrastarli.
Riservatezza Un'altra preoccupazione fondamentale. I modelli generativi possono talvolta memorizzare parti dei loro dati di addestramento e riprodurre involontariamente informazioni personali, come volti o nomi. Ciò solleva seri interrogativi etici sul fatto che i dati delle persone, soprattutto quelli provenienti da siti web pubblicamente acquisiti, fossero effettivamente destinati all'addestramento dell'IA.
Infine, provenienza dei dati, ovvero la tracciabilità della provenienza dei dati, è spesso poco chiara. Gli sviluppatori di intelligenza artificiale potrebbero non sempre sapere se i dati che utilizzano provengono da fonti etiche, sono regolarmente autorizzati o addirittura legalmente utilizzabili. Ciò crea rischi legali e reputazionali, soprattutto per le applicazioni commerciali.
Quando si valuta quale sfida deve affrontare l'intelligenza artificiale generativa rispetto ai dati, è chiaro che non si tratta solo di ostacoli tecnici, ma di questioni fondamentali riguardanti l'etica, la proprietà e la responsabilità nello sviluppo dell'intelligenza artificiale.
3. Qualità dei dati: Garbage in entrata, Garbage out

Quando si chiede quale sfida deve affrontare l'intelligenza artificiale generativa rispetto ai dati, uno dei problemi più urgenti è qualità dei datiI sistemi di intelligenza artificiale generativa, che producano immagini, testo o audio, sono validi solo quanto i dati su cui vengono addestrati. Se questi dati sono etichettati in modo errato, distorti, incompleti o di scarsa qualità, l'output rifletterà tali difetti, spesso in modi difficili da individuare finché non è troppo tardi.
Si consideri un modello di generazione di testo addestrato su dati medici obsoleti o inaccurati. L'IA potrebbe produrre consigli sanitari che sembrano plausibili ma sono clinicamente errati. Nella generazione di immagini, immagini di bassa qualità o scarsamente annotate possono portare a volti distorti, tonalità della pelle imprecise o rappresentazioni offensive, soprattutto in contesti sensibili come razza o genere. Ad esempio, un'IA addestrata con immagini di celebrità a bassa risoluzione potrebbe avere allucinazioni sui tratti del viso se applicata a persone reali. Nell'audio, dati di addestramento di scarsa qualità possono portare a una sintesi vocale robotica o incomprensibile, priva delle sfumature emotive richieste per l'accessibilità o gli assistenti virtuali.
Ciò è particolarmente dannoso in settori ad alto rischio come assistenza sanitaria E finanzaIn ambito sanitario, uno strumento diagnostico basato sull'intelligenza artificiale e basato su dati errati potrebbe identificare erroneamente i tumori, portando a trattamenti inadeguati. In ambito finanziario, un modello generativo basato su indicatori economici distorti potrebbe suggerire proiezioni irrealistiche, compromettendo le decisioni di investimento o i portafogli dei clienti.
Quindi, in breve, Il principio “garbage in, garbage out” è una risposta diretta alla sfida che l’intelligenza artificiale generativa deve affrontare rispetto ai dati: se i dati di input sono interrotti, l'intera pipeline di intelligenza artificiale ne risente.
Leggi la nostra guida approfondita su Generatore di modelli di moda AI per campagne globali
4. Problemi di privacy: il tuo volto è presente in un set di dati?

Un altro componente critico nella risposta quale sfida deve affrontare l'intelligenza artificiale generativa rispetto ai dati È riservatezza—in particolare, con quanta facilità i sistemi di intelligenza artificiale possono abusare o perdere informazioni informazioni di identificazione personale (PII)I modelli generativi, in particolare quelli che si occupano di riconoscimento facciale, clonazione vocale e generazione di contenuti personalizzati, spesso estraggono enormi volumi di dati pubblici. Il problema? Molti di questi dati includono immagini e dati personali che non sono mai stati destinati all'addestramento.
Ad esempio, qualcuno potrebbe scoprire che la propria foto, originariamente condivisa sui social media o su un blog, è stata riutilizzata da un'IA per generare volti sintetici, deepfake o avatar senza il suo consenso. Anche se i dati fossero tecnicamente "pubblici", non provenivano da fonti etiche né erano autorizzati al riutilizzo. Questa zona grigia ha scatenato reazioni negative da parte dell'opinione pubblica e un'indagine legale. Nel 2020, Clearview AI è stata citata in giudizio per aver raccolto miliardi di immagini facciali dal web senza consenso, sollevando preoccupazioni in merito alla sorveglianza e all'uso improprio dei dati.
Inoltre, i modelli di intelligenza artificiale generativa possono memorizzare e riprodurre inavvertitamente dati sensibili, come nomi, indirizzi e persino caratteristiche biometriche, se tali dati erano presenti durante l'addestramento. Ciò espone gli utenti a furto di identità, danni alla reputazione o profilazione non autorizzata.
Quando si valuta quale sfida deve affrontare l'intelligenza artificiale generativa rispetto ai dati, diventa chiaro che la riservatezza dei dati è più di una formalità legale: è una questione fondamentale di fiduciaStrumenti come Genera Persona con PiktID contribuire a risolvere questo problema consentendo agli utenti di rendere anonime le proprie immagini prima che vengano inserite in un set di dati, riducendo i rischi e preservando al contempo la libertà creativa.
Risorsa aggiuntiva: Generatore di volti per strumenti di marketing
5. Bias dei dati: perché l'equità è importante

Quando si chiede quale sfida deve affrontare l'intelligenza artificiale generativa rispetto ai dati, uno dei problemi più critici è bias nei set di datiL'intelligenza artificiale generativa apprende identificando schemi ricorrenti in grandi volumi di dati. Ma se questi dati sono distorti, favorendo determinati dati demografici, toni, lingue o caratteristiche visive, si ottengono risultati distorti che rafforzano stereotipi dannosi e portano a decisioni ingiuste.
Ad esempio, i modelli generativi utilizzati in Strumenti di assunzione basati sull'intelligenza artificiale hanno evidenziato pregiudizi di genere e razziali, spesso classificando i candidati uomini più in alto rispetto alle donne per ruoli di leadership. Analogamente, è stato riscontrato che i sistemi di riconoscimento facciale addestrati su set di dati sbilanciati identificano erroneamente gli individui appartenenti a minoranze molto più frequentemente rispetto agli individui bianchi. Queste discrepanze non sono semplicemente difetti tecnici: hanno un impatto diretto sulle persone reali, limitando l'accesso al lavoro, aumentando i rischi di sorveglianza e perpetuando le disuguaglianze.
La sfida principale risiede in bilanciare l'inclusività con i dati rappresentativiDa un lato, gli sviluppatori di IA devono garantire che tutte le comunità siano equamente rappresentate. Dall'altro, devono rispettare la privacy dei dati ed evitare il sovracampionamento di popolazioni sensibili. Quando ci chiediamo quale sfida affronti l'IA generativa in relazione ai dati, la risposta ai pregiudizi sociali radicati è in cima alla lista, perché dati distorti producono macchine distorte.
6. Provenienza dei dati: da dove provengono i dati?

Un'altra preoccupazione importante nel rispondere quale sfida deve affrontare l'intelligenza artificiale generativa rispetto ai dati è la questione di provenienza dei dati—la capacità di tracciare l'origine, la licenza e il percorso dei set di dati di addestramento. In parole povere, la provenienza è la "traccia documentale" che traccia la provenienza dei dati, come sono stati raccolti e se la loro provenienza è etica.
Ciò diventa particolarmente critico quando l’intelligenza artificiale generativa viene addestrata su dati recuperati da siti web, piattaforme social o archivi accademici, spesso senza la conoscenza o il consenso delle persone i cui dati vengono utilizzati. Ciò non solo pone sfide etiche, ma può anche innescare conseguenze legali, soprattutto quando si tratta di contenuti protetti da copyright o che consentono l'identificazione personale.
Uno dei problemi principali è il mancanza di trasparenza in molti set di dati di training. Gli sviluppatori potrebbero utilizzare fonti di terze parti prive di documentazione adeguata, rendendo impossibile verificare se i dati siano stati ottenuti in modo legale o etico. Ciò mina la fiducia nei sistemi di intelligenza artificiale generativa ed espone le aziende al controllo normativo.
Quando si considera quale sfida generativa Miglioratore del viso AI rispetto ai dati, la provenienza dei dati rappresenta una preoccupazione fondamentale. Senza una chiara identificazione delle fonti e del consenso, l'integrità dell'intero modello di IA è compromessa. Per ragioni etiche, legali e di performance, ogni dato utilizzato per addestrare l'IA deve essere tracciabile, documentato e allineato ai diritti dell'utente.
7. L'intelligenza artificiale generativa può funzionare senza grandi set di dati?

Una delle domande più urgenti nel mondo dell'apprendimento automatico è: L'intelligenza artificiale generativa può davvero funzionare senza enormi quantità di dati? La risposta breve è sì, ma non senza compromessi.
Tecniche come apprendimento a pochi scatti E apprendimento a colpo zero sono emersi come alternative ai tradizionali approcci basati su dati intensi. Questi metodi consentono ai modelli di eseguire attività con esempi diretti limitati o addirittura nulli, sfruttando conoscenze pre-addestrate e adattandosi rapidamente a nuovi scenari. Pur essendo promettenti, si basano ancora su un'ampia modelli preaddestrati che inizialmente erano stati addestrati su enormi set di dati. Quindi, la sfida non è stata del tutto aggirata, ma solo spostata a monte.
Questo ci riporta a una questione chiave: Quali sfide deve affrontare l'intelligenza artificiale generativa in relazione ai dati? La risposta sta nell'equilibrio tra innovazione e responsabilità. Anche le tecniche avanzate non possono eliminare completamente la necessità di set di dati diversificati, di provenienza etica e di alta qualitàSenza di essi, i risultati rischiano di essere imprecisi, parziali o addirittura dannosi.
Set di dati più piccoli, soprattutto se distorti o mal etichettati, possono limitare la generalizzabilità del modello e introdurre distorsioni nascoste. Inoltre, l'affidamento a dati raccolti pubblicamente o non verificati può portare a violazioni della privacy e problemi legali. Pertanto, l'approvvigionamento responsabile dei dati e gli strumenti di anonimizzazione diventano essenziali.
8. Soluzione in evidenza: rendere anonime le foto utilizzando Genera persona di PiktID

Per affrontare i rischi per la privacy associati ai dati di formazione, strumenti come Genera Persona con PiktID offrono un modo semplice per rendere anonimi i dati visivi senza comprometterne il realismo.
Che tu stia creando set di dati per la ricerca, il marketing, i test utente o la formazione sull'intelligenza artificiale, anonimizzazione dei dati personali non è più opzionale, è essenziale. Una delle risposte principali a quale sfida deve affrontare l'intelligenza artificiale generativa rispetto ai dati risiede negli strumenti che rispettano la privacy degli utenti e al contempo consentono l'innovazione.
Leggi di più su Esercitazione EraseID per apprendere e comprendere i passaggi necessari alla manipolazione dell'identità e delle espressioni facciali.
Come utilizzare Genera Persona di PiktID:
Passaggio 1: visita lo strumento
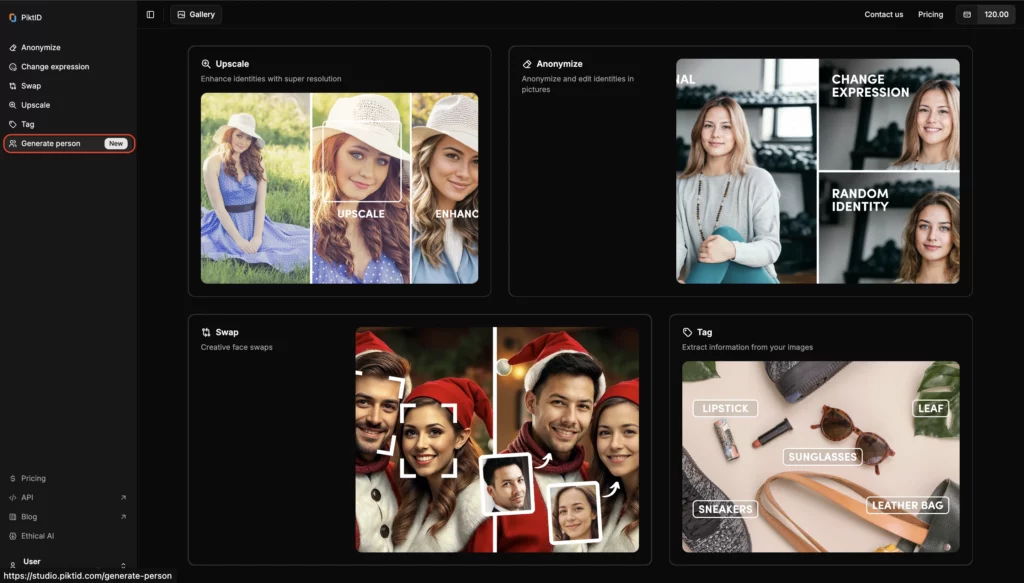
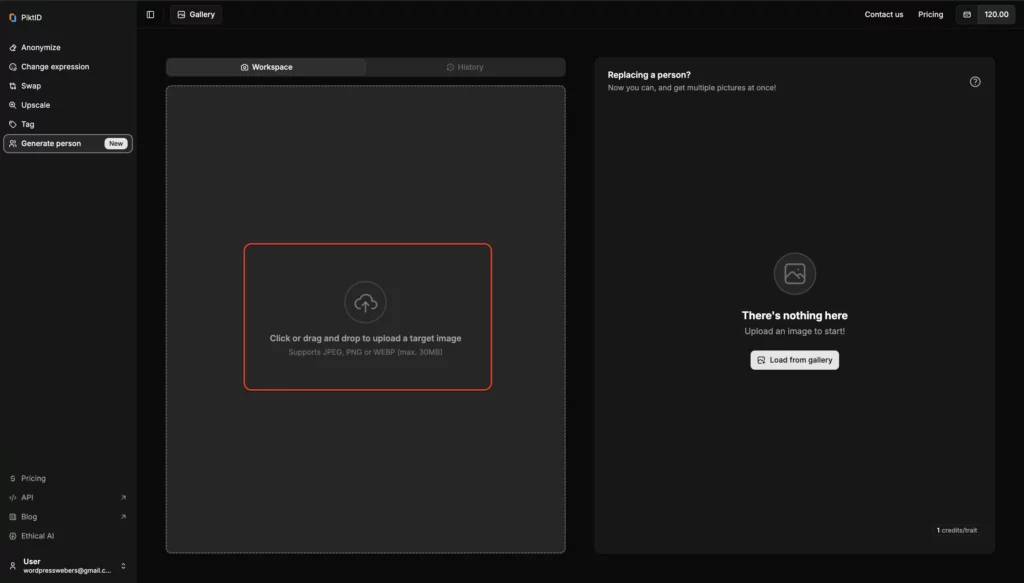
Passaggio 2: carica un'immagine
Trascina e rilascia o seleziona un'immagine direttamente dal tuo dispositivo. Può essere una foto personale o qualsiasi immagine che desideri rendere anonima.
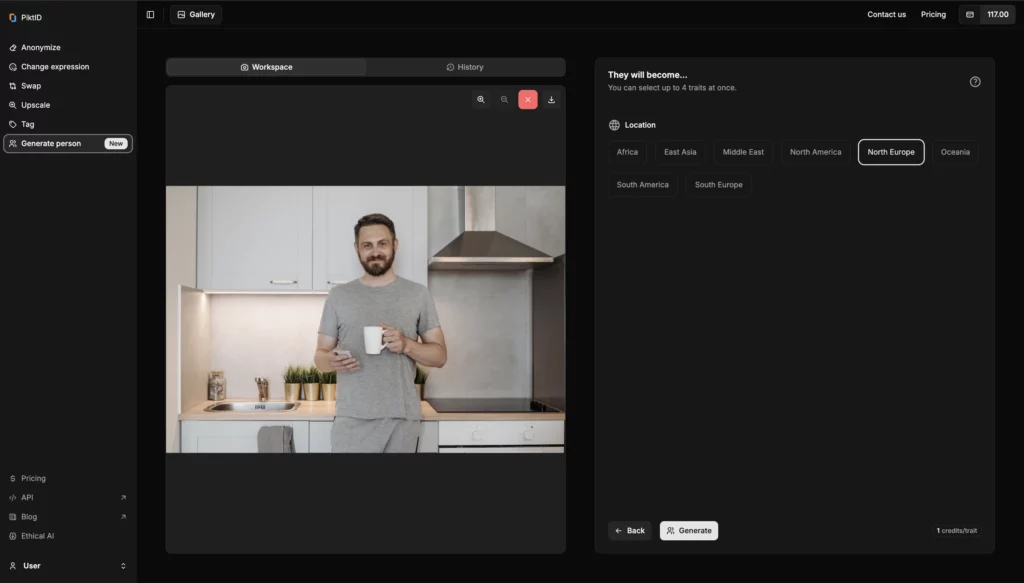
Passaggio 3: scegli una persona da sostituire o clonare
Utilizzando l'interfaccia a destra, seleziona la persona nella foto che desideri rendere anonima. Puoi anche clonare o modificare individui specifici.
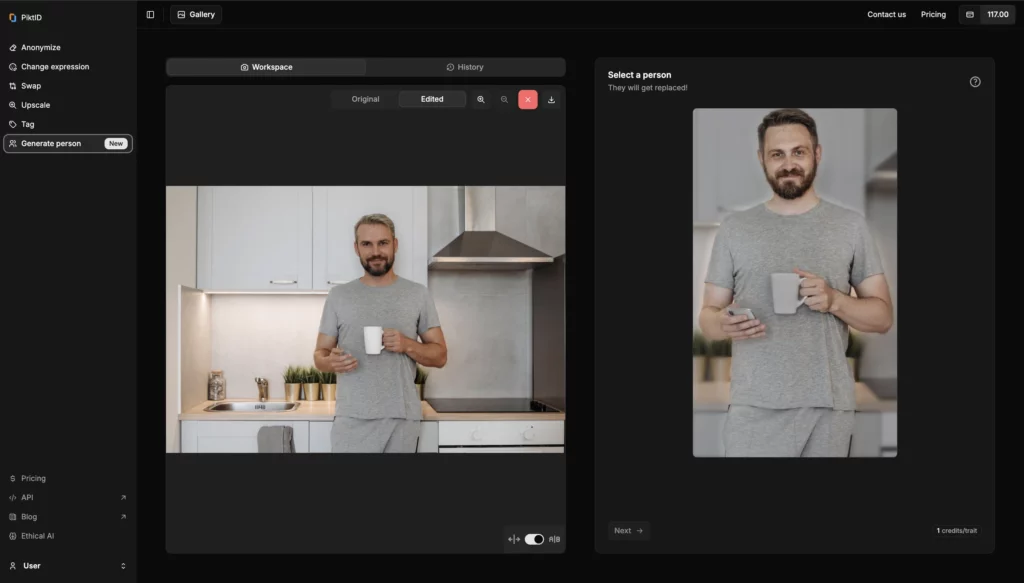
Passaggio 4: fare clic su Genera
Una volta selezionata, clicca sul pulsante "Genera". L'IA elaborerà l'immagine e ne creerà una versione anonima, che potrai visualizzare nella scheda Cronologia.
Vantaggi di Generate Person:
- Protegge la privacy: Sostituisce o modifica automaticamente i volti identificabili, riducendo il rischio di uso improprio.
- Ideale per la creazione di set di dati: Crea set di dati di addestramento dell'intelligenza artificiale senza esporre persone reali.
- Perfetto per test di marketing e UX: Mantenere il realismo umano senza violare le leggi sulla privacy.
- Non è necessario Photoshop: L'intelligenza artificiale gestisce tutte le modifiche, senza bisogno di competenze di progettazione.
Con l’inasprimento delle normative sulla privacy come il GDPR e il CCPA a livello globale, strumenti come Genera persona risolvere un problema fondamentale in quale sfida deve affrontare l'intelligenza artificiale generativa rispetto ai dati—vale a dire, etica dei dati, consenso e sicurezzaRendendo anonimi i dati facciali su larga scala, si compie un passo proattivo verso uno sviluppo responsabile dell'intelligenza artificiale.
9. Considerazioni finali: verso un'intelligenza artificiale etica e responsabile
Mentre continuiamo ad esplorare il potenziale trasformativo dell'intelligenza artificiale, una domanda critica rimane in primo piano: Quali sfide deve affrontare l'intelligenza artificiale generativa in relazione ai dati? La risposta risiede in una complessa rete di problematiche, che vanno dalla privacy e sicurezza dei dati alla distorsioni, al controllo di qualità e alla provenienza. Queste sfide non sono solo ostacoli tecnici, ma preoccupazioni etiche che influenzano l'affidabilità e la sostenibilità a lungo termine dei sistemi di intelligenza artificiale.
Senza dati puliti, diversificati e provenienti da fonti responsabili, anche i modelli di intelligenza artificiale generativa più avanzati possono produrre risultati inaccurati, discriminatori o invasivi. Ecco perché sviluppatori, aziende e singoli individui devono dare priorità a pratiche etiche in materia di dati.
È qui che entrano in gioco strumenti come Genera Persona con PiktID svolgono un ruolo fondamentale. Consentendo agli utenti di rendere anonimi i volti nelle immagini mantenendone la qualità visiva, lo strumento offre una soluzione pratica per proteggere i dati personali senza comprometterne la funzionalità. Risponde direttamente a una delle preoccupazioni più urgenti dell'IA generativa: l'uso e l'archiviazione non autorizzati di dati identificabili.
In un mondo in cui l'intelligenza artificiale sta diventando sempre più visiva e personale, anche gli utenti devono essere più informati. quali sfide deve affrontare l'intelligenza artificiale generativa rispetto ai dati è il primo passo verso la creazione di spazi digitali responsabili. Che tu stia creando set di dati, condividendo immagini o semplicemente curioso di sapere come vengono utilizzati i tuoi dati, essere proattivi è fondamentale.
Dai un'occhiata alla nostra guida su ID generato dall'IA di PiktID.
10. Richiedi i tuoi crediti gratuiti

Inizia a prendere il controllo della tua privacy oggi stesso con Genera Persona con PiktID—una soluzione sicura e intuitiva, progettata per rendere anonimi i dati facciali in pochi secondi.
Nessun download, nessuna complicazione: carica la tua foto, seleziona il volto da modificare e clicca su "Genera". In pochi clic, la tua immagine è pronta, con la privacy garantita.
Inizia subito e divertiti 10 crediti gratuiti, con nessun costo di registrazione richiestoEsplora la potenza degli strumenti di intelligenza artificiale etici che mettono al primo posto il controllo dell'utente e la dignità dei dati.
11. FAQ: Domande frequenti sull'intelligenza artificiale generativa e sui dati
D1: Qual è la sfida più grande che l'intelligenza artificiale generativa deve affrontare oggi?
La sfida più grande è bilanciare qualità dei dati, bias e privacy. Senza dati puliti, diversificati e provenienti da fonti etiche, l'intelligenza artificiale generativa può produrre risultati imprecisi o dannosi.
D2: Posso impedire che i miei dati vengano utilizzati nella formazione dell'intelligenza artificiale?
Sì, utilizzando strumenti incentrati sulla privacy come Generate Person di PiktID, puoi rendere anonime le tue foto. Questi strumenti garantiscono che i tuoi dati non vengano archiviati, riutilizzati o aggiunti ai set di dati di addestramento.
D3: Perché i pregiudizi nell'addestramento dell'intelligenza artificiale sono pericolosi?
Le distorsioni nei dati di training possono portare a risultati ingiusti, discriminatori o imprecisi. Ciò è particolarmente dannoso in settori come il riconoscimento facciale, le assunzioni, i prestiti e l'assistenza sanitaria, dove l'equità è fondamentale.
D4: Cosa rende un set di dati di alta qualità per l'intelligenza artificiale generativa?
Un set di dati di alta qualità è diversificato, ben etichettato, di provenienza etica e privo di rumore o duplicazioni. Dovrebbe rappresentare le variazioni del mondo reale senza rafforzare stereotipi o escludere gruppi chiave.
D5: Il mio volto è al sicuro quando lo carico su uno strumento di intelligenza artificiale?
Dipende dalla piattaforma. Strumenti come Generate Person di PiktID mettono al primo posto la privacy: non archiviano, riutilizzano o condividono le tue foto. Scegli sempre piattaforme con policy sui dati chiare e trasparenti.
D6: L'intelligenza artificiale generativa può funzionare senza grandi set di dati?
Non in modo efficace. Sebbene esistano tecniche di apprendimento a pochi scatti e a zero scatti, l'IA generativa funziona meglio con set di dati ampi e diversificati. Questi modelli necessitano di varietà per generare contenuti accurati e utili.
D7: In che modo l'intelligenza artificiale generativa utilizza i dati personali?
L'IA generativa può conservare tracce di dati personali provenienti dai set di addestramento, anche involontariamente. Se i dati non vengono resi anonimi o non vengono concessi, possono verificarsi rischi per la privacy e la replicazione non autorizzata di informazioni personali.
D8: Cos'è la provenienza dei dati e perché è importante nell'intelligenza artificiale?
La provenienza dei dati si riferisce al tracciamento della loro provenienza e del loro utilizzo. È essenziale per lo sviluppo etico dell'intelligenza artificiale, contribuendo a garantire trasparenza, legalità e responsabilità nei modelli di addestramento.