
1. El dilema de los datos en la IA generativa
La IA generativa se refiere a un subconjunto de la inteligencia artificial que crea nuevo contenido (imágenes, texto, audio, vídeo, etc.) basándose en patrones que aprende de los datos existentes, lo que plantea interrogantes sobre los desafíos que enfrenta con respecto a los datos. Herramientas como ChatGPT, DALL·E y Stable Diffusion son ejemplos populares que demuestran el potencial de la IA generativa en diferentes sectores. Sin embargo, esta impresionante tecnología conlleva una dependencia crítica: conjuntos de datos a gran escala y de alta calidad.
Para un buen rendimiento, los modelos de IA generativa deben entrenarse con grandes cantidades de datos que no solo sean limpios y diversos, sino que también provengan de fuentes éticas. Esto genera una tensión significativa entre innovación y responsabilidad. La mala calidad de los datos puede generar resultados engañosos; los conjuntos de datos sesgados pueden reforzar estereotipos perjudiciales; y el uso no regulado de datos personales puede generar problemas de privacidad.
En resumen, el mismo combustible que impulsa la IA generativa también plantea sus mayores vulnerabilidades.
Comprensión ¿Qué desafío enfrenta la IA generativa con respecto a los datos? Es esencial para construir sistemas de IA confiables. Este blog explora estos desafíos en profundidad, desde el sesgo y la privacidad de los datos hasta su procedencia, y también presenta una solución innovadora: Generar Persona por PiktIDEsta herramienta ayuda a los usuarios a proteger las identidades en conjuntos de datos al reemplazar o anonimizar a las personas en las imágenes sin comprometer el realismo.
2. ¿Qué desafío enfrenta la IA generativa con respecto a los datos?

¿Qué desafío enfrenta la IA generativa con respecto a los datos?
La IA generativa se enfrenta a importantes desafíos relacionados con los datos, como la mala calidad de los mismos, sesgos inherentes, la falta de privacidad y la procedencia poco clara de los mismos. Estos problemas pueden generar contenido defectuoso, riesgos éticos y una menor confianza pública en los sistemas de IA.
Uno de los mayores desafíos en la IA generativa es garantizar la calidad de los datosSi un modelo se entrena con conjuntos de datos ruidosos, mal etiquetados o incompletos, los resultados serán inexactos o sin sentido. Por ejemplo, una IA entrenada con imágenes faciales mal etiquetadas podría generar resultados distorsionados al solicitarle que cree nuevos rostros.
Luego viene inclinaciónUn problema generalizado que surge cuando los datos de entrenamiento sobrerrepresentan o subrepresentan a ciertos grupos. Un caso clásico es el de una IA de filtrado de currículums entrenada principalmente con solicitantes masculinos, lo que resultó en sugerencias de contratación discriminatorias. De igual manera, los modelos de generación de imágenes han mostrado tendencia a favorecer ciertas apariencias raciales o de género, reforzando estereotipos en lugar de cuestionarlos.
Privacidad Es otra preocupación fundamental. Los modelos generativos a veces pueden memorizar partes de sus datos de entrenamiento y reproducir involuntariamente información personal, como rostros o nombres. Esto plantea serias dudas éticas sobre si los datos personales, especialmente los de sitios web recopilados públicamente, se usaron para el entrenamiento de IA.
Por último, procedencia de los datosLa trazabilidad de la procedencia de los datos suele ser confusa. Los desarrolladores de IA no siempre saben si los datos que utilizan provienen de fuentes éticas, cuentan con las licencias adecuadas o incluso son legalmente utilizables. Esto genera riesgos legales y de reputación, especialmente para aplicaciones comerciales.
Al evaluar ¿Qué desafío enfrenta la IA generativa con respecto a los datos?Está claro que estos no son sólo obstáculos técnicos: son cuestiones fundamentales sobre la ética, la propiedad y la responsabilidad en el desarrollo de la IA.
3. Calidad de los datos: basura que entra, basura que sale

Al preguntar ¿Qué desafío enfrenta la IA generativa con respecto a los datos?Uno de los problemas más urgentes es calidad de los datosLos sistemas de IA generativa, ya sea que produzcan imágenes, texto o audio, son tan buenos como los datos con los que se entrenan. Si estos datos están mal etiquetados, sesgados, incompletos o son de mala calidad, el resultado reflejará esas fallas, a menudo de maneras difíciles de detectar hasta que es demasiado tarde.
Considere un modelo de generación de texto entrenado con datos médicos obsoletos o inexactos. La IA podría generar consejos de salud que parecen plausibles, pero que son médicamente incorrectos. En la generación de imágenes, las imágenes de baja calidad o mal anotadas pueden generar rostros distorsionados, tonos de piel imprecisos o representaciones ofensivas, especialmente en contextos sensibles como la raza o el género. Por ejemplo, una IA entrenada con imágenes de famosos de baja resolución podría alucinar rasgos faciales al aplicarlas a personas reales. En audio, los datos de entrenamiento de baja calidad pueden resultar en una síntesis de voz robótica o ininteligible, carente de la sutileza emocional necesaria para la accesibilidad o los asistentes virtuales.
Esto es particularmente perjudicial en campos de alto riesgo como cuidado de la salud y finanzasEn el ámbito sanitario, una herramienta de diagnóstico basada en IA, entrenada con datos erróneos, podría identificar tumores erróneamente, lo que conllevaría un tratamiento incorrecto. En el ámbito financiero, un modelo generativo entrenado con indicadores económicos sesgados podría sugerir proyecciones poco realistas, perjudicando las decisiones de inversión o las carteras de los clientes.
Así que en resumen, El principio de “basura que entra, basura que sale” es una respuesta directa al desafío que enfrenta la IA generativa con respecto a los datos.:Si los datos de entrada están dañados, todo el proceso de IA se ve afectado.
Lea nuestra guía detallada sobre Generador de modelos de moda con IA para campañas globales
4. Preocupaciones sobre la privacidad: ¿Aparece tu rostro en un conjunto de datos?

Otro componente crítico para responder ¿Qué desafío enfrenta la IA generativa con respecto a los datos? es privacidad—específicamente, con qué facilidad los sistemas de IA pueden hacer un mal uso o tener filtraciones información de identificación personal (PII)Los modelos generativos, especialmente los que se ocupan del reconocimiento facial, la clonación de voz y la generación de contenido personalizado, suelen extraer grandes cantidades de datos públicos. ¿El problema? Muchos de estos datos incluyen imágenes y datos personales que nunca se diseñaron para el entrenamiento.
Por ejemplo, alguien podría descubrir que su foto, originalmente compartida en redes sociales o un blog, ha sido reutilizada por una IA para generar rostros sintéticos, deepfakes o avatares sin su consentimiento. Incluso si los datos fueran técnicamente públicos, no se obtuvieron de forma ética ni se autorizó su reutilización. Esta zona gris ha provocado críticas públicas y escrutinio legal. En 2020, Clearview AI fue demandada por recopilar miles de millones de imágenes faciales de la web sin consentimiento, lo que generó preocupación por la vigilancia y el uso indebido de datos.
Además, los modelos de IA generativos pueden Memorizar y reproducir inadvertidamente datos confidenciales, como nombres, direcciones e incluso rasgos biométricos, si dichos datos estaban presentes durante el entrenamiento. Esto expone a los usuarios al robo de identidad, a daños a la reputación o a la elaboración de perfiles no autorizados.
Al evaluar ¿Qué desafío enfrenta la IA generativa con respecto a los datos?, queda claro que La privacidad de los datos es más que una formalidad legal: es una cuestión de confianza fundamental.Herramientas como Generar Persona por PiktID Podemos ayudar a solucionar este problema permitiendo a los usuarios anonimizar sus imágenes antes de que formen parte de un conjunto de datos, reduciendo el riesgo y preservando la libertad creativa.
Recurso adicional: Generador de rostros para herramientas de marketing
5. Sesgo de datos: por qué es importante la imparcialidad

Al preguntar ¿Qué desafío enfrenta la IA generativa con respecto a los datos?Uno de los problemas más críticos es sesgo en los conjuntos de datosLa IA generativa aprende identificando patrones en grandes volúmenes de datos. Pero si esos datos están sesgados (favoreciendo ciertos grupos demográficos, tonos, idiomas o características visuales), se generan resultados sesgados que refuerzan estereotipos dañinos y conducen a decisiones injustas.
Por ejemplo, los modelos generativos utilizados en Herramientas de contratación con inteligencia artificial Han mostrado sesgo de género y racial, priorizando a menudo a los candidatos hombres sobre las mujeres para puestos de liderazgo. De igual manera, se ha descubierto que los sistemas de reconocimiento facial entrenados con conjuntos de datos desequilibrados identifican erróneamente a personas pertenecientes a minorías con mucha mayor frecuencia que a personas blancas. Estas discrepancias no son simplemente fallas técnicas, sino que afectan directamente a las personas reales al limitar el acceso al empleo, aumentar los riesgos de vigilancia y perpetuar la desigualdad.
El desafío principal radica en Equilibrar la inclusión con datos representativosPor un lado, los desarrolladores de IA deben garantizar una representación justa de todas las comunidades. Por otro lado, deben respetar la privacidad de los datos y evitar el sobremuestreo de poblaciones sensibles. Al preguntarnos qué reto enfrenta la IA generativa con respecto a los datos, abordar el sesgo social integrado es prioritario, ya que los datos sesgados producen máquinas sesgadas.
6. Procedencia de los datos: ¿De dónde provienen los datos?

Otra preocupación importante a la hora de responder ¿Qué desafío enfrenta la IA generativa con respecto a los datos? ¿Es la cuestión de procedencia de los datos—la capacidad de rastrear el origen, las licencias y la trayectoria de los conjuntos de datos de entrenamiento. En pocas palabras, la procedencia es el registro documental que indica el origen de los datos, cómo se recopilaron y si su origen fue ético.
Esto se vuelve particularmente crítico cuando se entrena la IA generativa en datos extraídos de sitios web, plataformas sociales o repositorios académicos, a menudo sin el conocimiento ni el consentimiento de las personas cuyos datos se utilizan. Esto no solo plantea problemas éticos, sino que también puede tener consecuencias legales, especialmente cuando se trata de contenido protegido por derechos de autor o de identificación personal.
Una de las cuestiones centrales es la falta de transparencia En muchos conjuntos de datos de entrenamiento, los desarrolladores pueden usar fuentes de terceros que carecen de la documentación adecuada, lo que imposibilita verificar si los datos se obtuvieron de forma legal o ética. Esto mina la confianza en los sistemas de IA generativa y expone a las empresas al escrutinio regulatorio.
Al considerar ¿Qué desafío supone la generación? Mejorador facial con IA con respecto a los datosLa procedencia de los datos es una preocupación fundamental. Sin un origen claro y un consentimiento claro, la integridad de todo el modelo de IA se ve comprometida. Por razones éticas, legales y de rendimiento, todos los datos utilizados para entrenar la IA deben ser rastreables, documentados y estar alineados con los derechos de los usuarios.
7. ¿Puede la IA generativa funcionar sin grandes conjuntos de datos?

Una de las preguntas más urgentes en el mundo del aprendizaje automático es: ¿Puede la IA generativa funcionar realmente sin cantidades masivas de datos? La respuesta corta es sí, pero no sin concesiones.
Técnicas como aprendizaje de pocos disparos y aprendizaje de cero disparos Han surgido como alternativas a los enfoques tradicionales basados en datos. Estos métodos permiten que los modelos realicen tareas con ejemplos directos limitados o incluso nulos, aprovechando el conocimiento preentrenado y adaptándose rápidamente a nuevos escenarios. Si bien son prometedores, aún dependen de una gran cantidad de... modelos preentrenados que inicialmente se entrenaron con conjuntos de datos masivos. Por lo tanto, el desafío no se evita por completo, simplemente se traslada a etapas anteriores.
Esto nos lleva de nuevo a una cuestión clave: ¿Qué desafío enfrenta la IA generativa con respecto a los datos? La respuesta está en equilibrar la innovación con la responsabilidad. Ni siquiera las técnicas más avanzadas pueden eliminar por completo la necesidad de... Conjuntos de datos diversos, de origen ético y de alta calidadSin ellos, los resultados corren el riesgo de ser inexactos, sesgados o incluso perjudiciales.
Los conjuntos de datos más pequeños, especialmente si están sesgados o mal etiquetados, pueden limitar la generalización del modelo e introducir sesgos ocultos. Además, la dependencia de datos extraídos públicamente o no verificados Puede dar lugar a violaciones de la privacidad y problemas legales. Por lo tanto, la obtención responsable de datos y las herramientas de anonimización se vuelven esenciales.
8. Solución destacada: Anonimizar fotos con Generate Person de PiktID

Para abordar los riesgos de privacidad asociados con los datos de entrenamiento, se utilizan herramientas como Generar Persona por PiktID Ofrecen una forma perfecta de anonimizar datos visuales sin comprometer el realismo.
Ya sea que esté creando conjuntos de datos para investigación, marketing, pruebas de usuarios o capacitación en IA, anonimización de datos personales ya no es opcional, es esencial. Una de las principales respuestas a ¿Qué desafío enfrenta la IA generativa con respecto a los datos? radica en herramientas que respetan la privacidad del usuario al tiempo que permiten la innovación.
Leer más sobre Tutorial de EraseID Aprender y comprender los pasos involucrados en la manipulación de la identidad y las expresiones faciales.
Cómo utilizar Generar Persona de PiktID:
Paso 1: Visita la herramienta
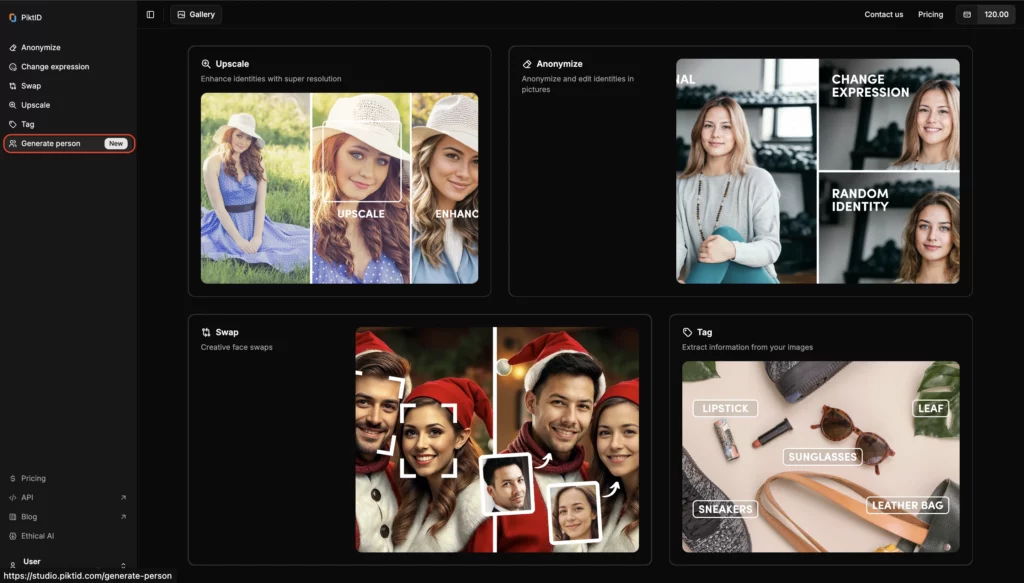
Paso 2: Subir una imagen
Arrastra y suelta o selecciona una imagen directamente desde tu dispositivo. Puede ser una foto personal o cualquier imagen que quieras anonimizar.
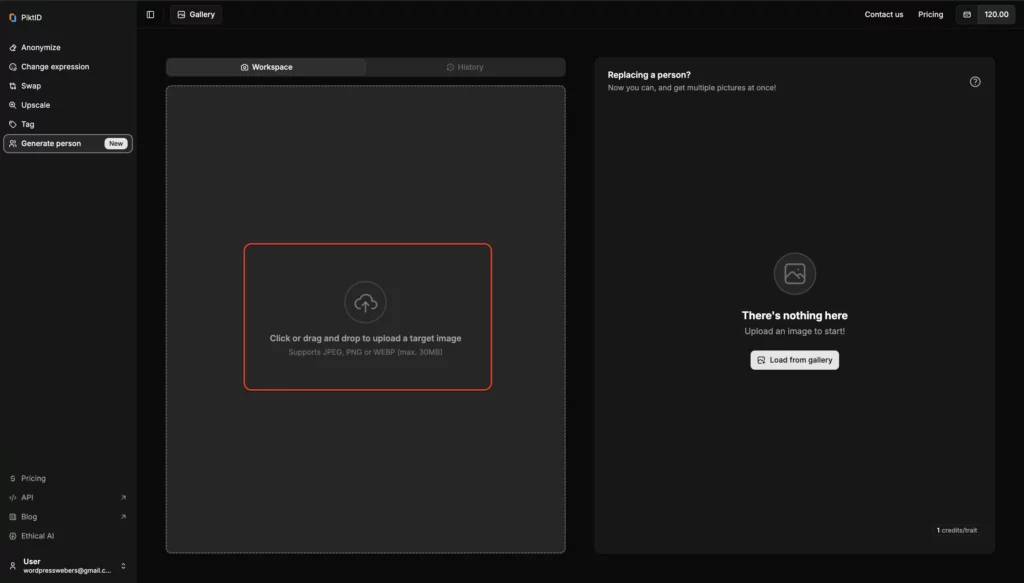
Paso 3: Elige una persona para reemplazar o clonar
En la interfaz derecha, selecciona a la persona de la foto que quieres anonimizar. También puedes clonar o modificar a personas específicas.
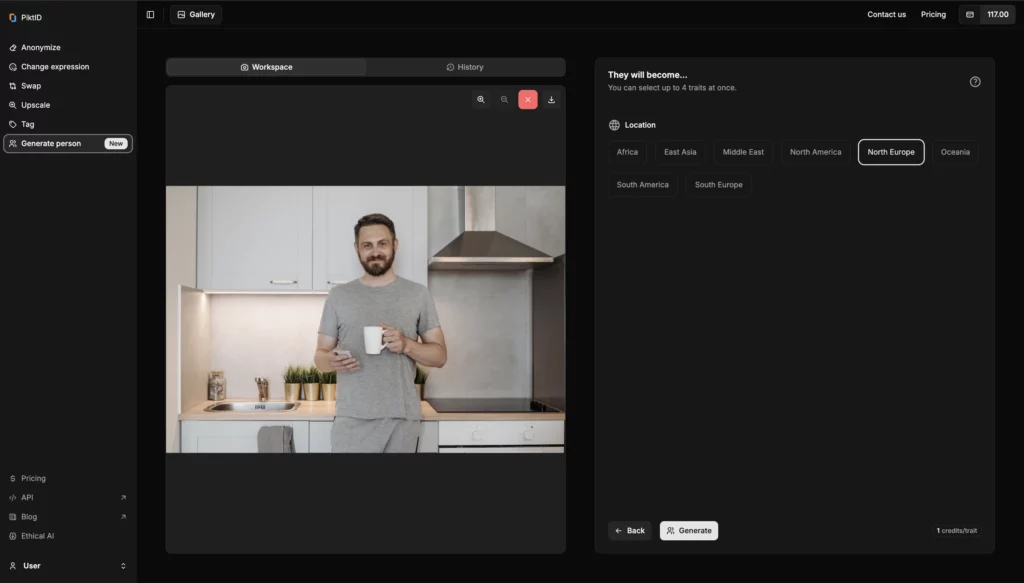
Paso 4: Haga clic en Generar
Una vez seleccionada, haz clic en el botón "Generar". La IA procesará la imagen y creará una versión anónima, que podrás consultar en la pestaña Historial.
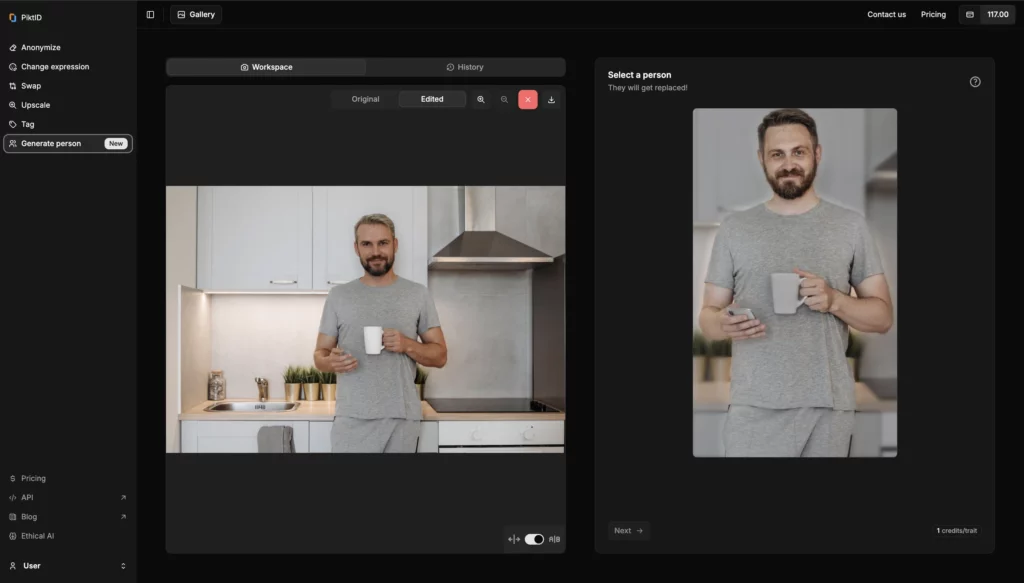
Beneficios de Generate Person:
- Protege la privacidad:Reemplaza o altera automáticamente las caras identificables, lo que reduce el riesgo de uso indebido.
- Ideal para la creación de conjuntos de datos:Cree conjuntos de datos de entrenamiento de IA sin exponer a individuos reales.
- Perfecto para marketing y pruebas de UX:Mantener el realismo humano sin violar las leyes de privacidad.
- No se necesita Photoshop:La IA maneja todas las ediciones, no se requieren habilidades de diseño.
A medida que las regulaciones de privacidad como GDPR y CCPA se endurecen a nivel mundial, herramientas como Generar Persona resolver un problema central en ¿Qué desafío enfrenta la IA generativa con respecto a los datos?-a saber, Ética de datos, consentimiento y seguridadAl anonimizar los datos faciales a gran escala, se da un paso proactivo hacia el desarrollo responsable de la IA.
9. Reflexiones finales: Hacia una IA ética y responsable
A medida que continuamos explorando el potencial transformador de la inteligencia artificial, una pregunta crítica permanece en primer plano: ¿Qué desafío enfrenta la IA generativa con respecto a los datos? La respuesta reside en una compleja red de problemas, que abarca desde la privacidad y la seguridad de los datos hasta el sesgo, el control de calidad y la procedencia. Estos desafíos no son solo obstáculos técnicos, sino también preocupaciones éticas que condicionan la fiabilidad y la viabilidad a largo plazo de los sistemas de IA.
Sin datos limpios, diversos y de origen responsable, incluso los modelos de IA generativa más avanzados pueden generar resultados inexactos, discriminatorios o invasivos. Por eso, tanto desarrolladores como empresas y particulares deben priorizar las prácticas éticas de datos.
Aquí es donde entran en juego herramientas como Generar Persona por PiktID Desempeñan un papel fundamental. Al permitir a los usuarios anonimizar rostros en imágenes, manteniendo la calidad visual, la herramienta ofrece una solución práctica para proteger los datos personales sin comprometer la funcionalidad. Aborda directamente una de las preocupaciones más urgentes de la IA generativa: el uso y almacenamiento no autorizados de datos identificables.
En un mundo donde la IA se vuelve cada vez más visual y personal, los usuarios también deben estar más informados. Comprensión ¿Qué desafío enfrenta la IA generativa con respecto a los datos? Es el primer paso para crear espacios digitales responsables. Ya sea que estés creando conjuntos de datos, compartiendo imágenes o simplemente sintiendo curiosidad por cómo se utilizan tus datos, ser proactivo es clave.
Echa un vistazo a nuestra guía sobre Identificación generada por IA por PiktID.
10. Reclama tus créditos gratis

Comience a tomar el control de su privacidad hoy mismo con Generar Persona por PiktID—una solución segura y fácil de usar diseñada para anonimizar datos faciales en segundos.
Sin descargas ni complicaciones: solo sube tu foto, selecciona la cara que quieres cambiar y pulsa "generar". En unos pocos clics, tu imagen estará lista, con total privacidad.
Empieza ahora y disfruta 10 créditos gratis, con No se requiere costo de registroExplore el poder de las herramientas de IA ética que priorizan el control del usuario y la dignidad de los datos.
11. Preguntas frecuentes: Preguntas comunes sobre IA generativa y datos
P1: ¿Cuál es el mayor desafío que enfrenta la IA generativa hoy en día?
El mayor desafío es equilibrar la calidad, el sesgo y la privacidad de los datos. Sin datos limpios, diversos y de origen ético, la IA generativa puede producir resultados inexactos o perjudiciales.
P2: ¿Puedo evitar que mis datos se utilicen en el entrenamiento de IA?
Sí, con herramientas centradas en la privacidad como Generate Person de PiktID, puedes anonimizar tus fotos. Estas herramientas garantizan que tus datos no se almacenen, reutilicen ni añadan a los conjuntos de datos de entrenamiento.
P3: ¿Por qué es peligroso el sesgo en el entrenamiento de IA?
El sesgo en los datos de entrenamiento puede generar resultados injustos, discriminatorios o inexactos. Esto es especialmente perjudicial en áreas como el reconocimiento facial, la contratación, los préstamos y la atención médica, donde la imparcialidad es fundamental.
P4: ¿Qué hace que un conjunto de datos sea de alta calidad para la IA generativa?
Un conjunto de datos de alta calidad es diverso, está bien etiquetado, proviene de fuentes éticas y no presenta ruido ni duplicaciones. Debe representar las variaciones del mundo real sin reforzar estereotipos ni excluir grupos clave.
P5: ¿Está mi rostro seguro cuando lo cargo en una herramienta de IA?
Depende de la plataforma. Herramientas como Generate Person de PiktID priorizan la privacidad: no almacenan, reutilizan ni comparten tus fotos. Elige siempre plataformas con políticas de datos claras y transparentes.
P6: ¿Puede la IA generativa funcionar sin grandes conjuntos de datos?
No de forma eficaz. Si bien existen técnicas de aprendizaje de pocos intentos y de cero intentos, la IA generativa funciona mejor con conjuntos de datos grandes y diversos. Estos modelos necesitan variedad para generar contenido preciso y útil.
P7: ¿Cómo utiliza la IA generativa los datos personales?
La IA generativa puede retener rastros de datos personales de los conjuntos de entrenamiento, incluso de forma involuntaria. Si los datos no se anonimizan ni se autorizan, pueden generar riesgos de privacidad y la replicación no autorizada de información personal.
P8: ¿Qué es la procedencia de los datos y por qué es importante en la IA?
La procedencia de los datos se refiere al seguimiento de su procedencia y su uso. Es esencial para el desarrollo ético de la IA, ya que ayuda a garantizar la transparencia, la legalidad y la rendición de cuentas en los modelos de entrenamiento.